
Build your own reinforcement learning agent that plays Super Mario

Who doesn’t love the Super Mario game?
I mean, everyone loves this game, right? Even if anyone has not played this game, at least they might have heard about this.
Today we will be building a reinforcement learning agent that will learn to play this game.
Prerequisites
Before starting, you should be familiar with the python programming language, and at least know how ML algorithm works. Reinforcement learning is a subset of machine learning, which I call “actual machine learning”. I mean, all the definition of ML fits reinforcement learning. All those pictures that you see about teaching a machine to do some task, that’s reinforcement learning.
All that to say, I am not going to talk more about RL in this story, as this is just to teach you guys how to build your own agent. You can get more knowledge from elsewhere about the basics of RL (there are tons of resources). I am just going to focus on Q-learning in Mario’s environment.
Environment Setup
The first thing that you need is a super Mario environment. We are going to use this gym environment which is super cool and super duper easy to use.
https://pypi.org/project/gym-super-mario-bros/
Install this env on your local machine:
pip install gym-super-mario-bros
Now that you have an environment, next thing is to install other requirements and create the file where we’re going to store our code.
Since we are building a Deep Q-learning agent, we are going to use TensorFlow to build the model. And we are dealing with a gym so we need an OpenAI gym as well (You can find all the requirements in our GitHub repo).
Building a model
Let’s import a few things and set up our DQNAgent model.
from collections import deque
from tensorflow.keras.models import Sequential, load_model, save_model
from tensorflow.keras.layers import Dense, Activation, Flatten, Conv2D
from tensorflow.keras.optimizers import Adam
import numpy as np
import randomAs discussed above, we are going to use TensorFlow to create our deep learning model. Let’s create our Agent class.
class DQNAgent:
def __init__(self, state_size, action_size):
# Create variables for our agent
self.state_space = state_size
self.action_space = action_size
self.memory = deque(maxlen=5000)
self.gamma = 0.8
self.chosenAction = 0# Exploration vs explotation
self.epsilon = 0.1
self.max_epsilon = 1
self.min_epsilon = 0.01
self.decay_epsilon = 0.0001# Building Neural Networks for Agent
self.main_network = self.build_network()
self.target_network = self.build_network()
self.update_target_network()Now here we have a few class variables that we are going to use inside our DQNAgent class. Here:
state_space is our vector containing coordinates for our environment spaceaction_space is our vector containing action space i.e., which action we can takememory is our memory spacegamma is our normalizing parameterchoosenAction is our current chosen action
Other variables there are the hyper-parameters that we require for our exploration vs exploitation phase. You can experiment with those parameters on your own time.
And after that, we have our objects.
Now let’s build our methods.
In ourbuild_network method, we are going to build our neural-net layers.
def build_network(self):
model = Sequential()
model.add(
Conv2D(64, (4, 4), strides=4, padding="same", input_shape=self.state_space)
)
model.add(Activation("relu"))model.add(Conv2D(64, (4, 4), strides=2, padding="same"))
model.add(Activation("relu"))model.add(Conv2D(64, (3, 3), strides=1, padding="same"))
model.add(Activation("relu"))
model.add(Flatten())model.add(Dense(512, activation="relu"))
model.add(Dense(256, activation="relu"))
model.add(Dense(self.action_space, activation="linear"))model.compile(loss="mse", optimizer=Adam())
return modelIf you have built any neural network using TF before, then this should be familiar to you. If not then there are a lot of other tutorials for that as we are not going deep into all that here.
Now we build out our train method.
def train(self, batch_size):
# minibatch from memory
minibatch = random.sample(self.memory, batch_size)# Get variables from batch so we can find q-value
for state, action, reward, next_state, done in minibatch:
target = self.main_network.predict(state)
print(target)if done:
target[0][action] = reward
else:
target[0][action] = reward + self.gamma * np.amax(
self.target_network.predict(next_state)
)
self.main_network.fit(state, target, epochs=1, verbose=0)Okay, so in this method, what we are doing is:
- sampling a minibatch
- randomly let our model make a prediction of the next state given the current state
- check if we have reached the target or not
- if done then we are good; we set our action
- if not then we get our possible action by applying a Q-learning algorithm
- Now from that action, we train our neural net
This is the main thing that we have to understand. After this, we have a few other helper methods that help in acting upon the current prediction, doing some exploration+exploitation, and updating the weights of our target network. You will find the full code in my GitHub Repo.
Result
Here is a demo of how this all looks:
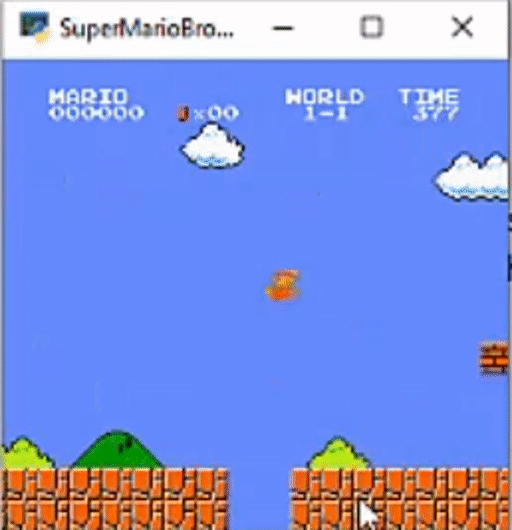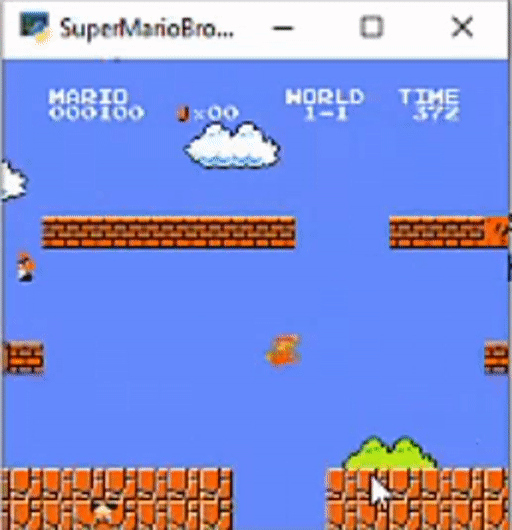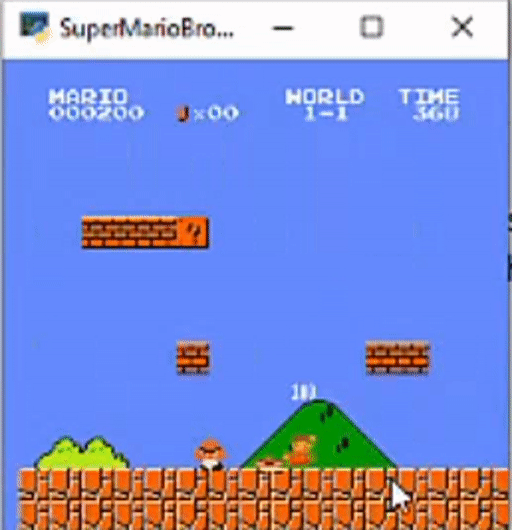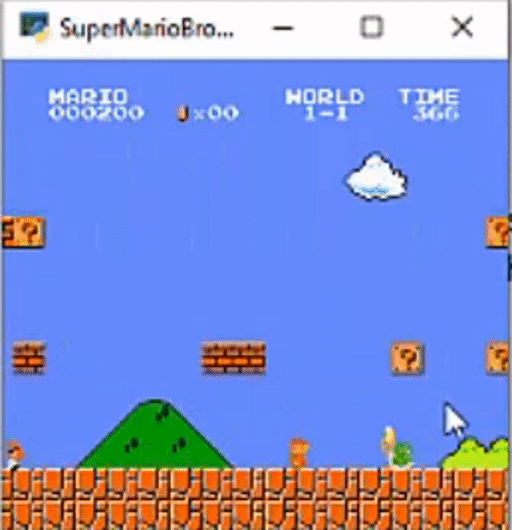
Here is a GitHub link for this project. Thanks Everyone!

Comments ()